The Better Way to load data
When we are loading lists in out web-apps, we usually do the following. Our app makes a fetch request to a server, waits for all the data to arrive, maybe the app validates it, and then displays the items.
import { const TodosSchema: z.ZodArray<z.ZodObject<{
description: z.ZodString;
done: z.ZodBoolean;
}, "strip", z.ZodTypeAny, {
description: string;
done: boolean;
}, {
description: string;
done: boolean;
}>, "many">
type Todo = {
description: string;
done: boolean;
}
function display(todo: Todo): voiddisplay } from "./render"
const const response: Responseresponse = await function fetch(input: string | URL | Request, init?: RequestInit | undefined): Promise<Response> (+1 overload)fetch("/todos"); //fetch
const const data: anydata = await const response: Responseresponse.Body.json(): Promise<any>json(); //wait
const const todos: {
description: string;
done: boolean;
}[]
const TodosSchema: z.ZodArray<z.ZodObject<{
description: z.ZodString;
done: z.ZodBoolean;
}, "strip", z.ZodTypeAny, {
description: string;
done: boolean;
}, {
description: string;
done: boolean;
}>, "many">
ZodType<{ description: string; done: boolean; }[], ZodArrayDef<ZodObject<{ description: ZodString; done: ZodBoolean; }, "strip", ZodTypeAny, { description: string; done: boolean; }, { ...; }>>, { ...; }[]>.parse(data: unknown, params?: Partial<ParseParams> | undefined): {
description: string;
done: boolean;
}[]
const data: anydata); //validate
for (const const todo: {
description: string;
done: boolean;
}
const todos: {
description: string;
done: boolean;
}[]
function display(todo: {
description: string;
done: boolean;
}): void
const todo: {
description: string;
done: boolean;
}
But what if there are hundreds of items and the connection to the server is slow. If we wait for the entire response to arrive the user is going to see absolutely nothing for several seconds, and then see all the items at once. This feels sluggish. Unfortunately, for anyone taking the subway, this is a daily experience.

There might be a better way though. We don’t actually need to wait for all the data before we start displaying it. Once the data for the first item has made it over the network, we should be able display it. Having the items trickle in as the data arrives over the network would be a much nicer user experience.
In this post we are going to implement this using streams.
Quick note: In the Javascript world there are two different Stream APIs: Node Streams, and Web streams. Node Streams only work in Node, whereas Web Streams work both in Browsers and Node. Also, web-streams are sometimes called WHATWG-streams, after the standards organisation, It’s a mess.
We will be using web-streams.
Fortunately this won’t be that hard.
Our trusty fetch API is designed to make streaming easy. response.body is actually a stream that will give you access to the raw data coming in over the network, as it is coming in.
Let’s visualise that by logging each chunk of data as it arrives. We can access a stream’s data by getting it’s reader and waiting for a value to arrive. Once a value arrives we log it and again wait for the next value, and then the next value, etc, until the stream is done.
const const response: Responseresponse = await function fetch(input: string | URL | Request, init?: RequestInit | undefined): Promise<Response> (+1 overload)fetch('/list');
const const stream: ReadableStream<Uint8Array>stream = const response: Responseresponse.Body.body: ReadableStream<Uint8Array> | nullbody!;
const const reader: ReadableStreamDefaultReader<Uint8Array>reader = const stream: ReadableStream<Uint8Array>stream.ReadableStream<Uint8Array>.getReader(): ReadableStreamDefaultReader<Uint8Array> (+2 overloads)getReader(); //Get reader (boilerplate)
while (true) {
const { const value: Uint8Array | undefinedvalue, const done: booleandone } = await const reader: ReadableStreamDefaultReader<Uint8Array>reader.ReadableStreamDefaultReader<Uint8Array>.read(): Promise<ReadableStreamReadResult<Uint8Array>>read(); //wait for value
if (const done: booleandone) break;
var console: ConsoleThe `console` module provides a simple debugging console that is similar to the
JavaScript console mechanism provided by web browsers.
The module exports two specific components:
* A `Console` class with methods such as `console.log()`, `console.error()` and `console.warn()` that can be used to write to any Node.js stream.
* A global `console` instance configured to write to [`process.stdout`](https://nodejs.org/docs/latest-v24.x/api/process.html#processstdout) and
[`process.stderr`](https://nodejs.org/docs/latest-v24.x/api/process.html#processstderr). The global `console` can be used without importing the `node:console` module.
_**Warning**_: The global console object's methods are neither consistently
synchronous like the browser APIs they resemble, nor are they consistently
asynchronous like all other Node.js streams. See the [`note on process I/O`](https://nodejs.org/docs/latest-v24.x/api/process.html#a-note-on-process-io) for
more information.
Example using the global `console`:
```js
console.log('hello world');
// Prints: hello world, to stdout
console.log('hello %s', 'world');
// Prints: hello world, to stdout
console.error(new Error('Whoops, something bad happened'));
// Prints error message and stack trace to stderr:
// Error: Whoops, something bad happened
// at [eval]:5:15
// at Script.runInThisContext (node:vm:132:18)
// at Object.runInThisContext (node:vm:309:38)
// at node:internal/process/execution:77:19
// at [eval]-wrapper:6:22
// at evalScript (node:internal/process/execution:76:60)
// at node:internal/main/eval_string:23:3
const name = 'Will Robinson';
console.warn(`Danger ${name}! Danger!`);
// Prints: Danger Will Robinson! Danger!, to stderr
```
Example using the `Console` class:
```js
const out = getStreamSomehow();
const err = getStreamSomehow();
const myConsole = new console.Console(out, err);
myConsole.log('hello world');
// Prints: hello world, to out
myConsole.log('hello %s', 'world');
// Prints: hello world, to out
myConsole.error(new Error('Whoops, something bad happened'));
// Prints: [Error: Whoops, something bad happened], to err
const name = 'Will Robinson';
myConsole.warn(`Danger ${name}! Danger!`);
// Prints: Danger Will Robinson! Danger!, to err
```console.Console.log(message?: any, ...optionalParams: any[]): void (+1 overload)Prints to `stdout` with newline. Multiple arguments can be passed, with the
first used as the primary message and all additional used as substitution
values similar to [`printf(3)`](http://man7.org/linux/man-pages/man3/printf.3.html)
(the arguments are all passed to [`util.format()`](https://nodejs.org/docs/latest-v24.x/api/util.html#utilformatformat-args)).
```js
const count = 5;
console.log('count: %d', count);
// Prints: count: 5, to stdout
console.log('count:', count);
// Prints: count: 5, to stdout
```
See [`util.format()`](https://nodejs.org/docs/latest-v24.x/api/util.html#utilformatformat-args) for more information.log(const value: Uint8Arrayvalue);
}We now see see a bunch of Uint8Arrays in the console. This is the raw binary data arriving over the network.

But we want text, so let’s convert the raw data to text. We can modify a stream’s data using a TransformStream. A TransformStream takes in a stream, runs some logic on each chunk of data as it arrives, and writes the result to an outgoing stream. In our case, we want a TransformStream that takes in a stream of raw binary data and outputs a stream of strings. This is such a common task that there actually is a built in one, the TextDecoderStream. Let’s use that. Don’t worry, we will be creating our own TransformStreams later on.
Let’s hook the TextDecoder up to our stream using the pipeThrough method. This will return a new stream with the transform applied.
const const stream: ReadableStream<string>stream = const request: Requestrequest.Body.body: ReadableStream<Uint8Array> | nullbody!.ReadableStream<Uint8Array>.pipeThrough<string>(transform: ReadableWritablePair<string, Uint8Array>, options?: StreamPipeOptions | undefined): ReadableStream<string>pipeThrough(new var TextDecoderStream: new (label?: string | undefined, options?: TextDecoderOptions | undefined) => TextDecoderStream`TextDecoderStream` class is a global reference for `import { TextDecoderStream } from 'node:stream/web'`.
https://nodejs.org/api/globals.html#class-textdecoderstreamTextDecoderStream());We now have a bunch of readable strings in the console.
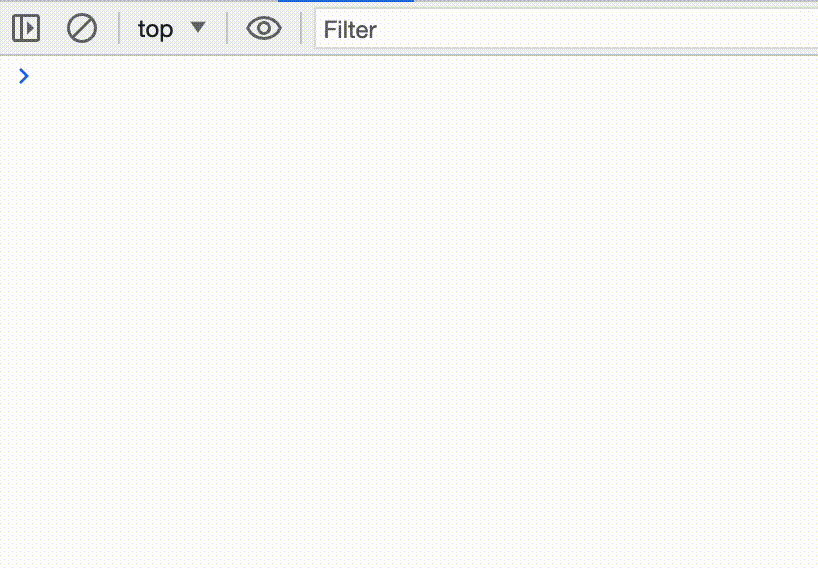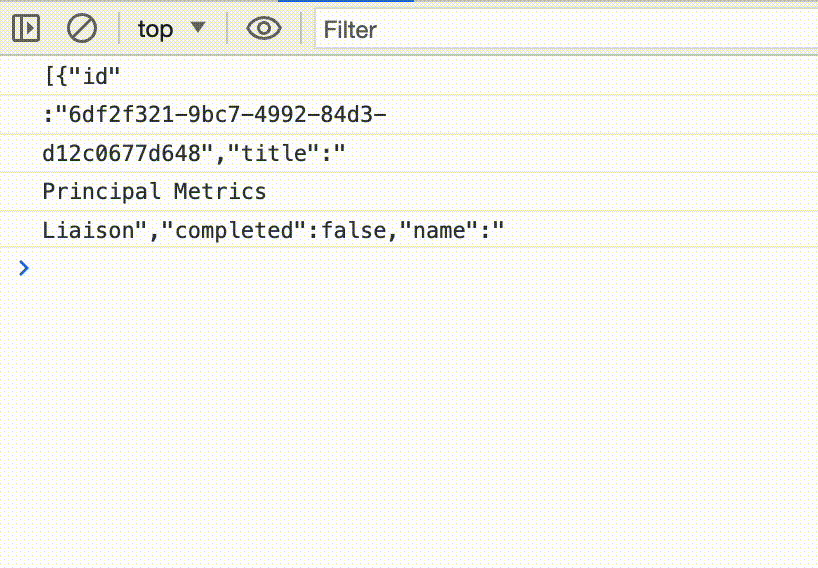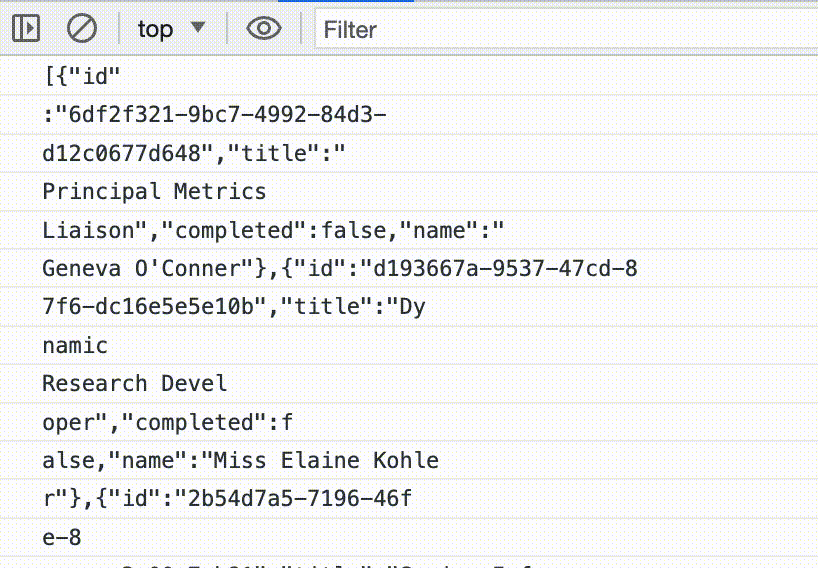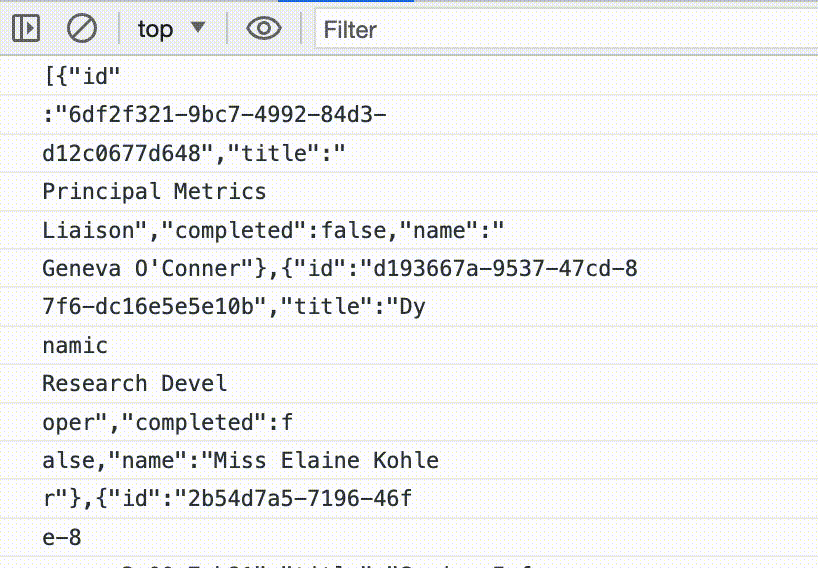
But we really want a stream of objects that represent our items. We can’t just JSON.parse each string-chunk, they don’t line up with the JSON structure; What we need is a streaming JSON parser.
Writing our own would be hard and undifferentiated work, so instead we’re going to use a library. There is a fantastic one called @streamparser/json-whatwg which can create a TransformStream that takes in json-data and returns parsed objects.
npm install @streamparser/json-whatwgWe can initialise the TransformStream using the JSONParser constructor. We want each object in our todo-array to be emitted one after the other as they trickle in so let’s configure the parser for that. We can provide a pattern of which paths should be emitted as the paths option; like a regex that runs on the paths. We want each child of the top-level array to be emitted. This can be expressed using the $.* pattern. The dollar-sign is always the top-level object, the array in our case, and the star is a wildcard that matches each direct child.
Let’s add this parser to our stream-chain. This parser can also do the text-decoding internally so we don’t need the TextDecoderStream anymore.
import { class JSONParserJSONParser } from "@streamparser/json-whatwg"
// ...
const const parser: JSONParserparser = new new JSONParser(opts?: JSONParserOptions | undefined, writableStrategy?: QueuingStrategy<any> | undefined, readableStrategy?: QueuingStrategy<any> | undefined): JSONParserJSONParser({ TokenParserOptions.paths?: string[] | undefinedpaths: ["$.*"] })
const const stream: ReadableStream<ParsedElementInfo>stream = const response: Responseresponse.Body.body: ReadableStream<Uint8Array> | nullbody!
.ReadableStream<Uint8Array>.pipeThrough<ParsedElementInfo>(transform: ReadableWritablePair<ParsedElementInfo, Uint8Array>, options?: StreamPipeOptions | undefined): ReadableStream<ParsedElementInfo>pipeThrough(const parser: JSONParserparser)Optional Performance optimization: Add
keepStack: false, stringBufferSize: undefinedalong with the paths option.
In the console we now see a bunch of weird objects. The value property in each one contains our list items in their fully parsed glory. JSONParser emits what it calls “ParsedElementInfo” objects, which contain the parsed values as well as some extra metadata. That’s what we’re seeing.
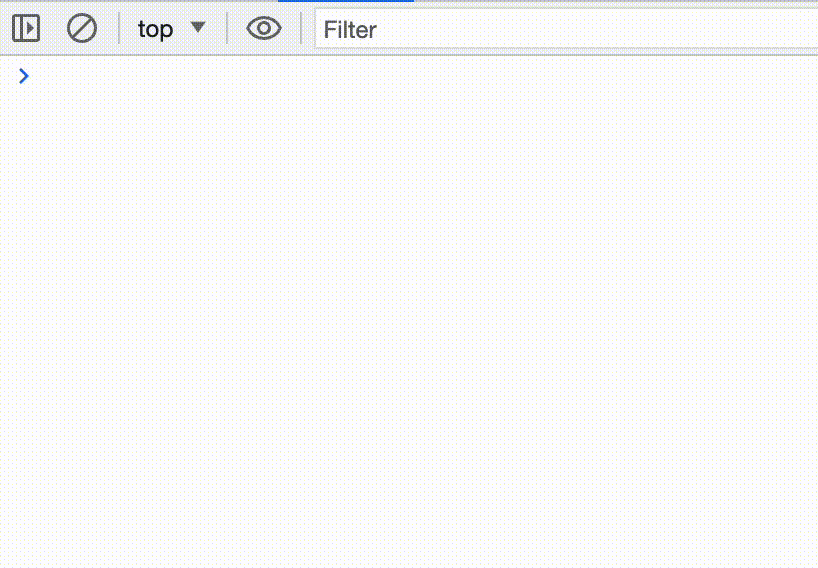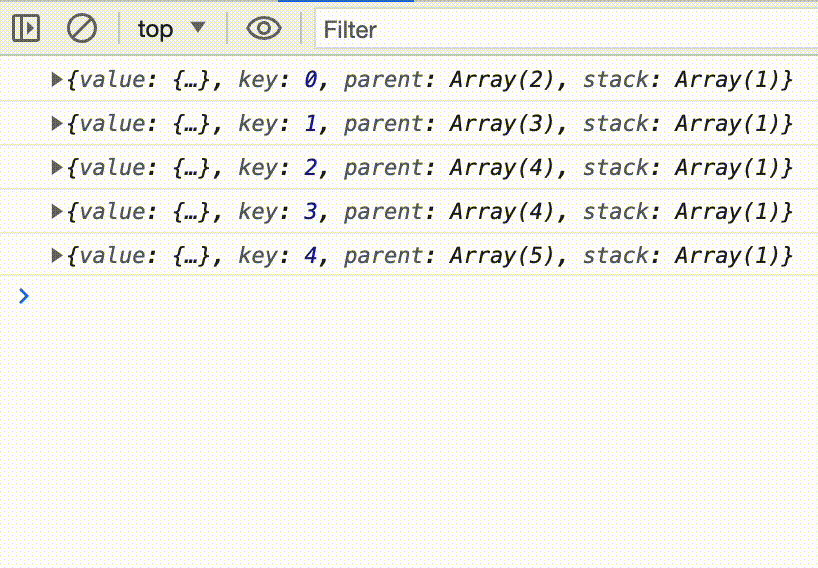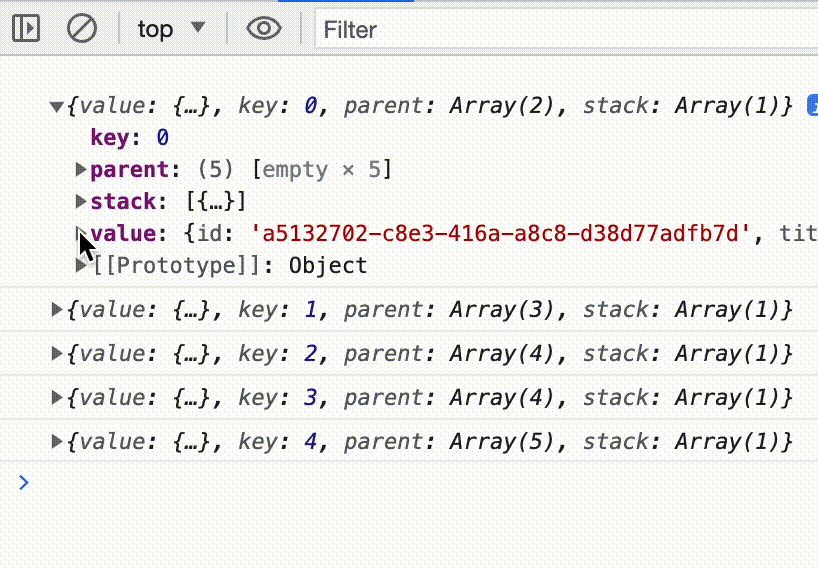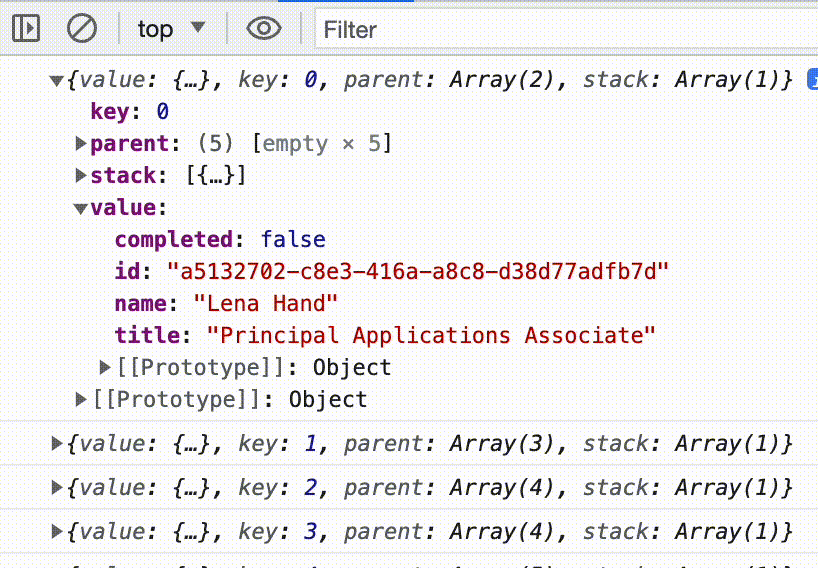
Since we only care about the parsed values, let’s map over each element in the stream using, you guessed it, another Transform Stream. This time we’ll create our own. The constructor takes an object with some lifecycle methods. The start method runs when the stream starts, the flush method runs if the stream is about to be closed, and the transform method runs whenever a new chunk of data arrives. We will only be using transform . It takes two arguments the first one is the chunk of incoming data, in our case that is the ParsedElementInfo object from the JSONParser, and the second one is a stream-controller for the output stream. The stream-controller is how we write to or close the output stream. Here we enqueue the value property of each parsed element.
const const mapToValueStream: TransformStream<any, any>mapToValueStream = new var TransformStream: new <any, any>(transformer?: Transformer<any, any> | undefined, writableStrategy?: QueuingStrategy<any> | undefined, readableStrategy?: QueuingStrategy<any> | undefined) => TransformStream<...>`TransformStream` class is a global reference for `import { TransformStream } from 'node:stream/web'`.
https://nodejs.org/api/globals.html#class-transformstreamTransformStream({
Transformer<any, any>.transform?: TransformerTransformCallback<any, any> | undefinedtransform(parsedElementInfo: anyparsedElementInfo, controller: TransformStreamDefaultController<any>controller) {
controller: TransformStreamDefaultController<any>controller.TransformStreamDefaultController<any>.enqueue(chunk?: any): voidenqueue(parsedElementInfo: anyparsedElementInfo.value);
}
});Let’s tack on our TransformStream and look at the console.
const const stream: ReadableStream<unknown>stream = const response: Responseresponse.Body.body: ReadableStream<Uint8Array> | nullbody!
.ReadableStream<Uint8Array>.pipeThrough<ParsedElementInfo>(transform: ReadableWritablePair<ParsedElementInfo, Uint8Array>, options?: StreamPipeOptions | undefined): ReadableStream<ParsedElementInfo>pipeThrough(const parser: JSONParserparser)
.ReadableStream<ParsedElementInfo>.pipeThrough<unknown>(transform: ReadableWritablePair<unknown, ParsedElementInfo>, options?: StreamPipeOptions | undefined): ReadableStream<unknown>pipeThrough(const valueStream: TransformStream<typeof ParsedElementInfo, unknown>valueStream);
That’s looking good already! We get list-items trickling in as the data is arriving over the network!
Let’s replace the log-statement with our rendering logic. I want to keep this post framework agnostic, so I won’t spend much time here. This is where you would hook into your UI framework.
import { function display(todo: Todo): voiddisplay } from "./render"
//...
while(true) {
const { const value: Todo | undefinedvalue, const done: booleandone } = await const reader: ReadableStreamDefaultReader<Todo>reader.ReadableStreamDefaultReader<Todo>.read(): Promise<ReadableStreamReadResult<Todo>>read();
if(const done: booleandone) break;
function display(todo: Todo): voiddisplay(const value: Todovalue)
}
Just what we wanted!
The original code we had did one more thing that we are not yet doing. It validated the data. Let’s add that. We’re going to need another TransformStream. This one is very similar to the one we already made. We need to validate each element in the stream, and write it to the output if and only if it’s valid. You could throw an error if an item is invalid; I’m just going to fail silently.
const const validateTodoStream: TransformStream<unknown, {
description: string;
done: boolean;
}>
var TransformStream: new <unknown, {
description: string;
done: boolean;
}>(transformer?: Transformer<unknown, {
description: string;
done: boolean;
}> | undefined, writableStrategy?: QueuingStrategy<unknown> | undefined, readableStrategy?: QueuingStrategy<...> | undefined) => TransformStream<...>
type Todo = {
description: string;
done: boolean;
}
Transformer<unknown, { description: string; done: boolean; }>.transform?: TransformerTransformCallback<unknown, {
description: string;
done: boolean;
}> | undefined
value: unknownvalue, controller: TransformStreamDefaultController<{
description: string;
done: boolean;
}>
controller: TransformStreamDefaultController<{
description: string;
done: boolean;
}>
TransformStreamDefaultController<{ description: string; done: boolean; }>.enqueue(chunk?: {
description: string;
done: boolean;
} | undefined): void
const TodoSchema: z.ZodObject<{
description: z.ZodString;
done: z.ZodBoolean;
}, "strip", z.ZodTypeAny, {
description: string;
done: boolean;
}, {
description: string;
done: boolean;
}>
ZodType<{ description: string; done: boolean; }, ZodObjectDef<{ description: ZodString; done: ZodBoolean; }, "strip", ZodTypeAny>, { description: string; done: boolean; }>.parse(data: unknown, params?: Partial<z.ParseParams> | undefined): {
description: string;
done: boolean;
}
value: unknownvalue));
} catch (function (local var) e: unknowne) {}
}
});Let’s add it to the stream-chain. Still Works!
import { class JSONParserJSONParser } from "@streamparser/json-whatwg";
declare const const response: Responseresponse : Response;
declare const const parser: JSONParserparser: class JSONParserJSONParser;
// ---cut-before-
const const stream: ReadableStream<Todo>stream = const response: Responseresponse.Body.body: ReadableStream<Uint8Array> | nullbody!
.ReadableStream<Uint8Array>.pipeThrough<ParsedElementInfo>(transform: ReadableWritablePair<ParsedElementInfo, Uint8Array>, options?: StreamPipeOptions | undefined): ReadableStream<ParsedElementInfo>pipeThrough(const parser: JSONParserparser)
.ReadableStream<ParsedElementInfo>.pipeThrough<unknown>(transform: ReadableWritablePair<unknown, ParsedElementInfo>, options?: StreamPipeOptions | undefined): ReadableStream<unknown>pipeThrough(const valueStream: TransformStream<typeof ParsedElementInfo, unknown>valueStream)
.ReadableStream<unknown>.pipeThrough<Todo>(transform: ReadableWritablePair<Todo, unknown>, options?: StreamPipeOptions | undefined): ReadableStream<Todo>pipeThrough(const validateTodoStream: TransformStream<unknown, Todo>validateTodoStream);We’ve now implemented all the original functionality in a streaming manner, but there is an opportunity to refactor here. Our two TransformStreams are very similar. They each execute a mapping function over every element, and emit the result. Let’s DRY that up. We’re going to make a helper called MapStream that takes the mapping-function as an argument and returns a TransformStream that runs it for each chunk. If it throws, we ignore the element.
// helpers.ts
export function MapStream<I, O>(map: (i: I) => O): TransformStream<I, O> {
return new TransformStream({
transform(chunk, controller) {
try {
controller.enqueue(map(chunk));
} catch (e) {}
}
});
}We can now rewrite both our TransformStreams using the helper.
import { function MapStream<I, O>(map: (i: I) => O): TransformStream<I, O>MapStream } from "./helpers"
//...
const const stream: ReadableStream<{
description: string;
done: boolean;
}>
const response: Responseresponse.Body.body: ReadableStream<Uint8Array> | nullbody!
.ReadableStream<Uint8Array>.pipeThrough<ParsedElementInfo>(transform: ReadableWritablePair<ParsedElementInfo, Uint8Array>, options?: StreamPipeOptions | undefined): ReadableStream<ParsedElementInfo>pipeThrough(const parser: JSONParserparser)
.ReadableStream<ParsedElementInfo>.pipeThrough<any>(transform: ReadableWritablePair<any, ParsedElementInfo>, options?: StreamPipeOptions | undefined): ReadableStream<any>pipeThrough(MapStream<ParsedElementInfo, any>(map: (i: ParsedElementInfo) => any): TransformStream<ParsedElementInfo, any>MapStream(result: ParsedElementInforesult => result: ParsedElementInforesult.value))
.ReadableStream<any>.pipeThrough<{
description: string;
done: boolean;
}>(transform: ReadableWritablePair<{
description: string;
done: boolean;
}, any>, options?: StreamPipeOptions | undefined): ReadableStream<...>
MapStream<unknown, {
description: string;
done: boolean;
}>(map: (i: unknown) => {
description: string;
done: boolean;
}): TransformStream<unknown, {
description: string;
done: boolean;
}>
const TodoSchema: z.ZodObject<{
description: z.ZodString;
done: z.ZodBoolean;
}, "strip", z.ZodTypeAny, {
description: string;
done: boolean;
}, {
description: string;
done: boolean;
}>
ZodType<{ description: string; done: boolean; }, ZodObjectDef<{ description: ZodString; done: ZodBoolean; }, "strip", ZodTypeAny>, { description: string; done: boolean; }>.parse(data: unknown, params?: Partial<z.ParseParams> | undefined): {
description: string;
done: boolean;
}
Very expressive, isn’t it?
With that, our implementation is done. But there is one more thing I would like to refactor; this while loop at the bottom. According to the spec, you’re supposed to be able to consume streams using a for await of loop, but not everyone implements this.
for await (const const todo: Todotodo of const stream: AsyncGenerator<Todo, any, unknown>stream) {
const display: (todo: Todo) => voiddisplay(const todo: Todotodo);
}
Let’s write another helper that let’s us use the nicer syntax. If you’ve never used async-generators before, this will look unintelligible. That’s ok, this is entirely optional; Just stick with the while loop.
// helpers.ts
export async function* function asIterable<T>(stream: ReadableStream<T>): AsyncGenerator<T>asIterable<function (type parameter) T in asIterable<T>(stream: ReadableStream<T>): AsyncGenerator<T, any, unknown>T>(stream: ReadableStream<T>stream: interface ReadableStream<R = any>This Streams API interface represents a readable stream of byte data. The Fetch API offers a concrete instance of a ReadableStream through the body property of a Response object.
`ReadableStream` class is a global reference for `import { ReadableStream } from 'node:stream/web'`.
https://nodejs.org/api/globals.html#class-readablestreamReadableStream<function (type parameter) T in asIterable<T>(stream: ReadableStream<T>): AsyncGenerator<T, any, unknown>T>): interface AsyncGenerator<T = unknown, TReturn = any, TNext = unknown>AsyncGenerator<function (type parameter) T in asIterable<T>(stream: ReadableStream<T>): AsyncGenerator<T, any, unknown>T> {
const const reader: ReadableStreamDefaultReader<T>reader = stream: ReadableStream<T>stream.ReadableStream<T>.getReader(): ReadableStreamDefaultReader<T> (+2 overloads)getReader();
while (true) {
const { const value: T | undefinedvalue, const done: booleandone } = await const reader: ReadableStreamDefaultReader<T>reader.ReadableStreamDefaultReader<T>.read(): Promise<ReadableStreamReadResult<T>>read();
if (const done: booleandone) break;
yield const value: Tvalue;
}
}We can now use for await (const todo of asIterable(stream)) to asynchronously loop over the elements in the stream. I find this easier to read, since there is no control-flow.
// @filename: helpers.ts
declare function MapStream<I, O>(map: (i: I) => O) : TransformStream<I, O>
declare function asIterable<T>(stream: ReadableStream<T>): AsyncGenerator<T>
export { MapStream, asIterable }
// @filename: fetch.ts
type Todo = { description: string, done: boolean }
declare const stream: ReadableStream<Todo>
declare const display: (todo: Todo) => void
// ---cut-before---
import { MapStream, asIterable } from "./helpers"
//...
for await (const todo of asIterable(stream)) {
display(todo);
}The final code looks like this:
import { class JSONParserJSONParser } from '@streamparser/json-whatwg';
import { function MapStream<I, O>(map: (i: I) => O): TransformStream<I, O>MapStream, function asIterable<T>(stream: ReadableStream<T>): AsyncGenerator<T>asIterable } from './helpers';
import { const TodoSchema: z.ZodObject<{
description: z.ZodString;
done: z.ZodBoolean;
}, "strip", z.ZodTypeAny, {
description: string;
done: boolean;
}, {
description: string;
done: boolean;
}>
const response: Responseresponse = await function fetch(input: string | URL | Request, init?: RequestInit | undefined): Promise<Response> (+1 overload)fetch('/todos.json');
const const parser: JSONParserparser = new new JSONParser(opts?: JSONParserOptions | undefined, writableStrategy?: QueuingStrategy<any> | undefined, readableStrategy?: QueuingStrategy<any> | undefined): JSONParserJSONParser({
TokenParserOptions.paths?: string[] | undefinedpaths: ['$.*']
});
const const stream: ReadableStream<{
description: string;
done: boolean;
}>
const response: Responseresponse.Body.body: ReadableStream<Uint8Array> | nullbody!
.ReadableStream<Uint8Array>.pipeThrough<ParsedElementInfo>(transform: ReadableWritablePair<ParsedElementInfo, Uint8Array>, options?: StreamPipeOptions | undefined): ReadableStream<ParsedElementInfo>pipeThrough(const parser: JSONParserparser)
.ReadableStream<ParsedElementInfo>.pipeThrough<any>(transform: ReadableWritablePair<any, ParsedElementInfo>, options?: StreamPipeOptions | undefined): ReadableStream<any>pipeThrough(MapStream<ParsedElementInfo, any>(map: (i: ParsedElementInfo) => any): TransformStream<ParsedElementInfo, any>MapStream((result: ParsedElementInforesult) => result: ParsedElementInforesult.value))
.ReadableStream<any>.pipeThrough<{
description: string;
done: boolean;
}>(transform: ReadableWritablePair<{
description: string;
done: boolean;
}, any>, options?: StreamPipeOptions | undefined): ReadableStream<...>
MapStream<unknown, {
description: string;
done: boolean;
}>(map: (i: unknown) => {
description: string;
done: boolean;
}): TransformStream<unknown, {
description: string;
done: boolean;
}>
const TodoSchema: z.ZodObject<{
description: z.ZodString;
done: z.ZodBoolean;
}, "strip", z.ZodTypeAny, {
description: string;
done: boolean;
}, {
description: string;
done: boolean;
}>
ZodType<{ description: string; done: boolean; }, ZodObjectDef<{ description: ZodString; done: ZodBoolean; }, "strip", ZodTypeAny>, { description: string; done: boolean; }>.parse(data: unknown, params?: Partial<ParseParams> | undefined): {
description: string;
done: boolean;
}
const todo: {
description: string;
done: boolean;
}
asIterable<{
description: string;
done: boolean;
}>(stream: ReadableStream<{
description: string;
done: boolean;
}>): AsyncGenerator<{
description: string;
done: boolean;
}, any, unknown>
const stream: ReadableStream<{
description: string;
done: boolean;
}>
const display: (todo: Todo) => voiddisplay(const todo: {
description: string;
done: boolean;
}
A few observations to close out.
- On slow connections, the Streaming version is both faster to show stuff to the user and also finishes earlier, since the parsing and validation happen in parallel with the fetching. On fast connections, the performance difference is negligible.
- Once the
MapStreamandasIterablehelpers are defined, the streaming version of the code isn’t meaningfully longer. The effort for both versions is about the same. - The bundle size for the streaming versions is slightly larger than the non-streaming version since we need to ship the JSONParser (+20kB). This isn’t always worth it. On sites with long session times it likely is worth it, since the extra code is only sent once and every subsequent request can be sped up. In PWAs, where your code is already cached on the client, streaming is a no brainer.
There is a lot more you can do with streams, I really encourage you to play around with them. They’re a really powerful idea that applies to much more than just data-fetching. I hope you’ve learned something and have a good day.